Kubernetes简介
Kubernetes简称K8S(因为k和s中间有8个字母),是一个开源的容器集群管理平台,基于Go语言编写。
使用K8S,将简化分布式系统上的容器应用部署,使得开发人员可以专注于业务软件,而非较为底层的负载均衡、服务监控等。因此,可以认为它是介于操作系统软件和应用软件之间的”中间件“。K8S具有强大的自动化机制,降低了系统后期的运维难度。
此外,K8S没有限定编程接口,无论Java、Go、C++还是Python编写的服务,都可以映射为K8S的Service。并且由于其对现有的语言、框架、中间件没有任何侵入性,使得服务易于迁移到K8S上。
本文力图使用通俗易懂的语言概括Kubernetes的一些概念。在阅读本文前,你至少需要对Linux、docker、容器、yaml/json等有所了解。
Kubernetes概貌认知
在遇到一项新技术时,笔者习惯于先搞清楚它“是什么“,为什么被发明出来,是如何使用和运作的。
为什么需要Kubernetes
如果读者对容器有所了解,并且有一定的使用经验,那么就很容易理解Kubernetes存在的理由。
容器是运行在物理机上的轻量化“虚拟机”,一般一个应用程序就会启用一个容器。由于各种原因,容器中的程序也许会出现错误,甚至容器和服务器本身会挂掉。在云数据中心有大量的服务器,每台服务器上可能运行着几十个乃至上百个容器,如果单纯靠运维人员去监视、操作每个容器,那肯定是不现实的。因此就需要更高一层的容器编排管理程序,来自动化地管理容器应用。
或许我们可以自己去搭建这个平台,不过Kubernetes的出现为我们省去了许多麻烦。有了Kubernetes,我们只需要安装和启动它的一组服务就可以了。开发或运维人员只需要编写一些yaml或json文件,指定集群的期望状态,然后在Terminal运行kubectl命令对集群进行操作,剩下的过程都由Kubernetes自动完成。这样,开发人员就可以专注于业务应用,而非与大量的服务器硬件和操作系统本身打交道,同时后期运维也变得非常简单。
Kubernetes的服务组成
通常至少需要启动以下的服务以构成完整的Kubernetes系统:
- etcd:数据库。平台内的各种数据、程序的状态在这里存储和交换。不过etcd并不是Kubernetes实现的,后者只是使用它作为平台的数据库。
- docker:Kubernetes管理的对象。准确来说管理的对象是容器,docker只是Kubernetes支持的容器运行时的其中一种。当然,它本身也不是Kubernetes实现的。
- kube-apiserver:各类资源的增、删、改、查、watch等操作的统一接口。
- kube-controller-manager:集群的管理控制中心,负责各类资源的管理。比如某个Node宕机时,controller-manager会发现故障并自动化修复,保证集群处在预期的工作状态。简单来说,它解决Pod数量和状态“对不对”的问题。
- kube-scheduler:负责POD的调度工作,负责将Controller Manager创建的Pod调度到具体的Node上。简单来说,它解决controller manager创建的Pod“去哪”的问题。
- kubelet:运行在Node上,管理下发到本节点的Pod本身及Pod中的容器。
- kube-proxy:Kubernetes集群内有大量的容器和服务,它们通过TCP相互通信,kube-proxy就负责解决通信的问题。
你可以通过Kubernetes官网的这张图来了解其整体结构:
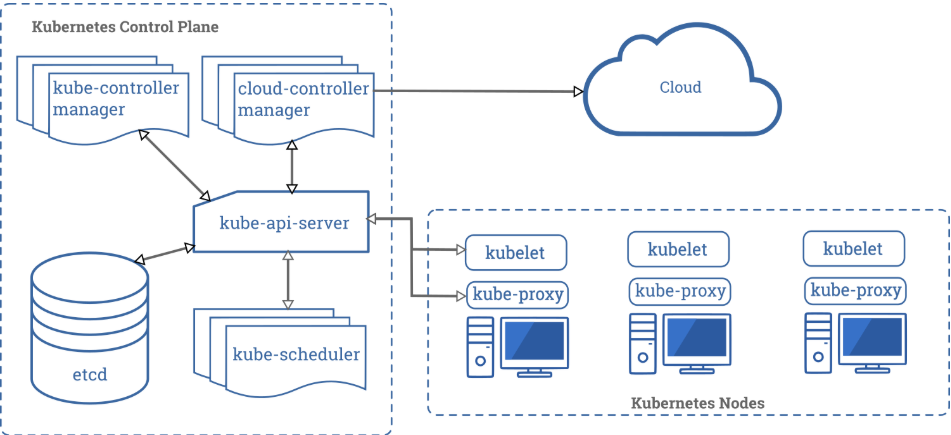
读者可以通过阅读笔者的上一篇博客《Kubernetes单机创建MySQL-Tomcat演示程序》,动手实践来了解整个Kubernetes到底是如何运转的。
Kubernetes关键概念
或许上一节的一些术语还让读者非常疑惑,现在我们一起来具体看看一些重要概念的意思。
集群和节点
一个集群就是数台运行着应用程序的服务器,每台服务器被称为一个节点,至少3个节点才可以称得上是一个集群。
节点可以是物理机,也可以是虚拟机(传统意义上的),只要能够运行docker和Kubernetes服务。
节点有2种:
- 主节点Master:是整个集群的管理中心。Master上运行的进程包括:
- etcd
- kube-apiserver
- kube-controller-manager
- kube-scheduler
- 工作节点Node:运行具体的工作负载(容器中的应用程序)。Node上运行的进程包括:
- 容器运行时
- kubelet
- kube-proxy
Tip:此处有一个小的歧义,工作节点Node直译也是节点。“节点”一词到底是Node和Master的合称,还是单指Node,英文语境下似乎是后者,而中文里似乎比较模糊。笔者目前习惯于将Node和Master都称作”节点“,而将Node称作”工作节点“,这样交流沟通时指代比较明确。
Node可以在运行期间动态加入集群,默认情况下kubelet会向Mater注册自己。一旦加入集群,kubelet会定时向Mater节点汇报自身状态,以便Master进行管理调度。
如果某个Node超过指定时间没有上报信息,就会被Master判定为失联。该Node的状态将被标记为Not Ready,上面的负载会被转移。
对象
Kubernetes对象是Kubernetes系统中的持久实体。Kubernetes使用这些实体来表示集群的状态,包括:
- 哪些容器正在运行,运行在那些Node上
- 容器应用可用的资源
- 关于应用如何运行的策略
一旦创建了对象,Kubernetes会确保对象存在。通过创建对象,可以告诉Kubernetes系统你希望集群的目标状态是什么样的。
一般在yaml或json文件中定义对象,再通过Kubernetes API来使用(增删改查)。有两种方式来操作对象(即调用API),一是通过kubectl命令行工具调用,二是在编程语言中调用——目前官方提供了Go和Python的库。
Tip:对象不是一个进程或一组进程,指示对象存在的是一段信息的记录(通常是etcd中或文件中)。
Name和UID
所有对象都用Name和UID来明确标识。
Name就是对象的名称,通常一部分是由用户在对象定义文件中自定义的。那么另一部分是什么?
可以思考这样一个问题:以上面的Pod为例,假如有5个myweb应用的副本(这非常正常,短时间内很可能有多个用户访问一个网页),如何区分它们?笔者理解的是,Kubernetes创建Pod时会在Name中加上一段随机的字符,以区分不同的副本,如myweb-w3ec4,myweb-t9p84等(笔者随便写的,具体的机制还没有学习到,大概也是哈希之类)。这有点类似于git的版本号。
从上面也可以看出,一个Name在同一时间只能被一个对象拥有。如果对象被删除,可以使用相同的Name创建新的对象。
UID则完全是由Kubernetes生成的。在Kubernetes集群的整个生命周期内,每个对象都拥有不同的UID。也就是说,不仅同一时刻所有的对象UID都不同,而且即便某个对象被删除后重新创建,也会拥有不同的UID。
Pod
Pod可以说是Kubernetes中最重要的对象,它是Kubernetes中的最小部署单元。Pod通常由一组容器构成,包括一个根容器,和其他一些共同完成业务功能的容器。如下图所示:
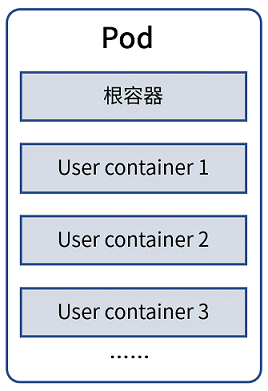
为什么不以容器本身作为管理的单元,而是又抽象出Pod?原因主要有以下几点:
- 一项业务功能通常是由好几个应用程序共同完成的,需要作为一个整体。但单个业务容器异常不能代表业务整体挂掉,难以判断一项业务是否正常进行。抽象为Pod之后,用根容器的状态代表整个Pod的状态解决了这个问题。
- Pod内部通过共享根容器挂载的卷,简化了业务容器间的通信。
- Pod内部共享根容器的IP,简化了与Pod之间(不同业务之间)的通信。
Pod的两种类型
Pod信息存放的位置,实际上对应了Pod的两种类型:普通Pod,静态Pod。
普通Pod被创建后,其信息会被存放在etcd数据库中,然后会被调度到具体的Node上进行绑定,该Node中的kubelet将其实例化成一组容器。默认情况下,如果一个容器出现问题,Kubernetes检测到后将重启整个Pod——实际上是重启Pod中的所有容器。如果Node宕机,则将在其他Node重新生成新的完全一样的Pod代替它。
与此相反,静态Pod则比较特殊,其信息存放在某个具体的Node上的一个具体文件中,只在此Node运行,不会被转移。
Pod的资源限额
可以对Pod使用的计算资源做限额,包括CPU和Memory两种。
CPU限额的单位是千分之一个CPU核心,记作m。通常一个容器的配额有100300m,即0.10.3个CPU核心。Memory限额的单位是内存字节数。
对配额限定有两个参数:
- Requets:资源的最小申请量,系统必须满足要求。
- Limits:资源最大允许使用的量,超过它可能会kill该容器并重启。
Service
Service是Kubernetes中另一种重要的对象,它定义了一种访问实体资源(如Pod)的策略,或者说入口,这就是通常说的“微服务”。
考虑一个图片处理的后台应用,它有3个副本。这些副本是可以互相代替的,也就是访问谁的效果都是一样的,甚至可能挂掉重启。前端不应该也没必要关心到底调用哪个副本,Service定义的统一入口实现了前后端的解耦。
Pod的IP会随着Pod本身的销毁和创建发生变化。与此相反,每个Service创建时都会被分配一个全局唯一的虚拟IP地址,称为Cluster-IP。在Service的整个生命周期内,该Cluster-IP不会发生变化。客户端实际上访问的是Service,并且我们还希望客户端能够通过名称去访问。
“通过名称而不是地址去访问”,这句话让读者有何联想?没错,就是DNS。用Service的Name与Service的Cluster-IP做一个DNS域名映射,这就是Kubernetes的服务发现机制。
参考资料:
《Kubernetes权威指南》(龚正等著)